 Last weekend after Saul and Ciera's wedding, I drove up to Pat, Grib, and Jesse's
house to which I hadn't previously been. I got in late and they'd just finished a UFC party. The next day Grib had to travel for work but the rest of us met Scott and Nicole, Jesse's girlfriend at
a place for breakfast. After that we went back to their place for some Rock Band which I hadn't played previously and Pat took the opportunity to show off his real life musical skills on the banjo.
Last weekend after Saul and Ciera's wedding, I drove up to Pat, Grib, and Jesse's
house to which I hadn't previously been. I got in late and they'd just finished a UFC party. The next day Grib had to travel for work but the rest of us met Scott and Nicole, Jesse's girlfriend at
a place for breakfast. After that we went back to their place for some Rock Band which I hadn't played previously and Pat took the opportunity to show off his real life musical skills on the banjo.
 This weekend, Jesse and Nicole are up visiting Seattle. On Friday, Sarah and I met up with them at the BluWater Bistro in Seattle which sits right on Lake Union. The view was nice although difficult to see from our table and overall I like the sister
restaurant in Kirkland better. They were both short visits but it was fun to see people again.
This weekend, Jesse and Nicole are up visiting Seattle. On Friday, Sarah and I met up with them at the BluWater Bistro in Seattle which sits right on Lake Union. The view was nice although difficult to see from our table and overall I like the sister
restaurant in Kirkland better. They were both short visits but it was fun to see people again.
 Last weekend while Sarah was up in Canada for a spa weekend with her sister and her sister's other bridesmaids, I went to Saul and Ciera's
wedding in Three Rivers, California near Sequoia National Park. I flew into Fresno picked up a rental car and my GPS device navigated me to a restaurant with the wedding location no where in sight.
"No problem," I thought, "I'll just call someone with an Internet connection and..." I had no cell reception. What did people do before GPS, Internet, and cell phones?
Last weekend while Sarah was up in Canada for a spa weekend with her sister and her sister's other bridesmaids, I went to Saul and Ciera's
wedding in Three Rivers, California near Sequoia National Park. I flew into Fresno picked up a rental car and my GPS device navigated me to a restaurant with the wedding location no where in sight.
"No problem," I thought, "I'll just call someone with an Internet connection and..." I had no cell reception. What did people do before GPS, Internet, and cell phones?
 A waitress in the restaurant pointed me down the road a bit to the wedding location which was outside overlooking a
river. Their wedding cake was made up like a mountain with two backpacks at the top and rope hanging down. Ciera's father married them and the ceremony was lovely. The music after included Code Monkey to which all the nerds were forced to get up and awkwardly dance.
A waitress in the restaurant pointed me down the road a bit to the wedding location which was outside overlooking a
river. Their wedding cake was made up like a mountain with two backpacks at the top and rope hanging down. Ciera's father married them and the ceremony was lovely. The music after included Code Monkey to which all the nerds were forced to get up and awkwardly dance.
 Besides getting to see Ciera and Saul who I hadn't seen in quite a while, I got to see Daniil and Val, Vlad, and Nathaniel. Since
last I saw Daniil and Val they had a child, Katie who is very cute and in whom I can see a lot of family resemblance. The always hilarious Vlad,
Daniil's brother, was there as well with his wife who I got to meet. Nathaniel, my manager from Vizolutions was there and I don't know if I've seen him since I moved to Washington. It was fun to
see him and meet his girlfriend who was kind enough to donate her extra male to male mini-phono cord so I could listen to my Zune in the rental car stereo on the drive back.
Besides getting to see Ciera and Saul who I hadn't seen in quite a while, I got to see Daniil and Val, Vlad, and Nathaniel. Since
last I saw Daniil and Val they had a child, Katie who is very cute and in whom I can see a lot of family resemblance. The always hilarious Vlad,
Daniil's brother, was there as well with his wife who I got to meet. Nathaniel, my manager from Vizolutions was there and I don't know if I've seen him since I moved to Washington. It was fun to
see him and meet his girlfriend who was kind enough to donate her extra male to male mini-phono cord so I could listen to my Zune in the rental car stereo on the drive back.
![['Neverending story' by Alexandre Duret-Lutz. A framed photo of books with the droste effect applied. Licensed under creative commons.]](http://farm1.static.flickr.com/90/252757784_3de44cbeb4_m_d.jpg) Information about URI Fragments, the portion of URIs
that follow the '#' at the end and that are used to navigate within a document, is scattered throughout various documents which I usually have to hunt down. Instead I'll link to them all here.
Information about URI Fragments, the portion of URIs
that follow the '#' at the end and that are used to navigate within a document, is scattered throughout various documents which I usually have to hunt down. Instead I'll link to them all here.
Definitions. Fragments are defined in the URI RFC which states that they're used to identify a secondary resource that is related to the primary resource identified by the URI as a subset of the primary, a view of the primary, or some other resource described by the primary. The interpretation of a fragment is based on the mime type of the primary resource. Tim Berners-Lee notes that determining fragment meaning from mime type is a problem because a single URI may contain a single fragment, however over HTTP a single URI can result in the same logical resource represented in different mime types. So there's one fragment but multiple mime types and so multiple interpretations of the one fragment. The URI RFC says that if an author has a single resource available in multiple mime types then the author must ensure that the various representations of a single resource must all resolve fragments to the same logical secondary resource. Depending on which mime types you're dealing with this is either not easy or not possible.
HTTP. In HTTP when URIs are used, the fragment is not included. The General Syntax section of the HTTP standard says it uses the definitions of 'URI-reference' (which includes the fragment), 'absoluteURI', and 'relativeURI' (which don't include the fragment) from the URI RFC. However, the 'URI-reference' term doesn't actually appear in the BNF for the protocol. Accordingly the headers like 'Request-URI', 'Content-Location', 'Location', and 'Referer' which include URIs are defined with 'absoluteURI' or 'relativeURI' and don't include the fragment. This is in keeping with the original fragment definition which says that the fragment is used as a view of the original resource and consequently only needed for resolution on the client. Additionally, the URI RFC explicitly notes that not including the fragment is a privacy feature such that page authors won't be able to stop clients from viewing whatever fragments the client chooses. This seems like an odd claim given that if the author wanted to selectively restrict access to portions of documents there are other options for them like breaking out the parts of a single resource to which the author wishes to restrict access into separate resources.
HTML. In HTML, the HTML mime type RFC defines HTML's fragment use which consists of fragments referring to elements with a corresponding 'id' attribute or one of a particular set of elements with a corresponding 'name' attribute. The HTML spec discusses fragment use additionally noting that the names and ids must be unique in the document and that they must consist of only US-ASCII characters. The ID and NAME attributes are further restricted in section 6 to only consist of alphanumerics, the hyphen, period, colon, and underscore. This is a subset of the characters allowed in the URI fragment so no encoding is discussed since technically its not needed. However, practically speaking, browsers like FireFox and Internet Explorer allow for names and ids containing characters outside of the defined set including characters that must be percent-encoded to appear in a URI fragment. The interpretation of percent-encoded characters in fragments for HTML documents is not consistent across browsers (or in some cases within the same browser) especially for the percent-encoded percent.
Text. Text/plain recently got a fragment definition that allows fragments to refer to particular lines or characters within a text document. The scheme no longer includes regular expressions, which disappointed me at first, but in retrospect is probably good idea for increasing the adoption of this fragment scheme and for avoiding the potential for ubiquitous DoS via regex. One of the authors also notes this on his blog. I look forward to the day when this scheme is widely implemented.
XML. XML has the XPointer framework to define its fragment structure as noted by the XML mime type definition. XPointer consists of a general scheme that contains subschemes that identify a subset of an XML document. Its too bad such a thing wasn't adopted for URI fragments in general to solve the problem of a single resource with multiple mime type representations. I wrote more about XPointer when I worked on hacking XPointer into IE.
SVG and MPEG. Through the Media Fragments Working Group I found a couple more fragment scheme definitions. SVG's fragment scheme is defined in the SVG documentation and looks similar to XML's. MPEG has one defined but I could only find it as an ISO document "Text of ISO/IEC FCD 21000-17 MPEG-12 FID" and not as an RFC which is a little disturbing.
AJAX. AJAX websites have used fragments as an escape hatch for two issues that I've seen. The first is getting a unique URL for versions of a page that are produced on the client by script. The fragment may be changed by script without forcing the page to reload. This goes outside the rules of the standards by using HTML fragments in a fashion not called out by the HTML spec. but it does seem to be inline with the spirit of the fragment in that it is a subview of the original resource and interpretted client side. The other hack-ier use of the fragment in AJAX is for cross domain communication. The basic idea is that different frames or windows may not communicate in normal fashions if they have different domains but they can view each other's URLs and accordingly can change their own fragments in order to send a message out to those who know where to look. IMO this is not inline with the spirit of the fragment but is rather a cool hack.
 It was warm and lovely out this past Saturday and Sarah I and went to a
new place for lunch, then to Kelsey Creek Park, and then out for Jane's birthday. We ate at Cafe
Pirouette which serves crepes and is done up with French decorations reminding me of my parent's house. We got in for just the end of lunch and saw the second to last customers, a gaggle of
older ladies leaving. I felt a little out of place with my "Longhorn [heart] RSS" t-shirt on. The food was good and in larger portions that I expected.
It was warm and lovely out this past Saturday and Sarah I and went to a
new place for lunch, then to Kelsey Creek Park, and then out for Jane's birthday. We ate at Cafe
Pirouette which serves crepes and is done up with French decorations reminding me of my parent's house. We got in for just the end of lunch and saw the second to last customers, a gaggle of
older ladies leaving. I felt a little out of place with my "Longhorn [heart] RSS" t-shirt on. The food was good and in larger portions that I expected.
 After that we went to Kelsey Creek Park and Farm. The park is hidden at the end of a quiet neighborhood, starts out with some tables and children's jungle gym
equipment, then there's a farm which includes a petting zoo, followed by many little trails going off into the forrest. There weren't too many animals out and the ones we did see didn't seem to
expect or want the sun and warm weather. We followed one of the trails for a bit and turned back before getting sun burned. You can see
my weekend photos mapped out on Live Maps.
After that we went to Kelsey Creek Park and Farm. The park is hidden at the end of a quiet neighborhood, starts out with some tables and children's jungle gym
equipment, then there's a farm which includes a petting zoo, followed by many little trails going off into the forrest. There weren't too many animals out and the ones we did see didn't seem to
expect or want the sun and warm weather. We followed one of the trails for a bit and turned back before getting sun burned. You can see
my weekend photos mapped out on Live Maps.
That night we went out with some friends for Jane's birthday. Eric was just back from the RSA conference and we met Jane and Eric and others at Palace Kitchen in Seattle located immediately adjascent to the monorail's route. The weather was still good so they left the large windows open through twilight and every so often you'd see the monorail pass by.
sequelguy posted a photo:

calendar.thenewstribune.com/bellevue-wa/venues/show/25896...
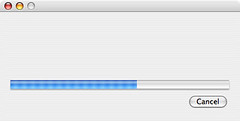 More of my thoughts have been stolen: In my
previous job the customer wanted a progress bar displayed while information was copied off of proprietary hardware, during which the software didn't get any indication of progress until the copy
was finished. I joked (mostly) that we could display a progress bar that continuously slows down and never quite reaches the end until we know we're done getting info from the hardware. The amount
of progress would be a function of time where as time approaches infinity, progress approaches a value of at most 100 percent.
More of my thoughts have been stolen: In my
previous job the customer wanted a progress bar displayed while information was copied off of proprietary hardware, during which the software didn't get any indication of progress until the copy
was finished. I joked (mostly) that we could display a progress bar that continuously slows down and never quite reaches the end until we know we're done getting info from the hardware. The amount
of progress would be a function of time where as time approaches infinity, progress approaches a value of at most 100 percent.
This is similar to Zeno's Paradox which says you can't cross a room because to do so first you must cross half the room, then you must cross half the remaining distance, then half the remaining again, and so on which means you must take an infinite number of steps. There's also an old joke inspired by Zeno's Paradox. The joke is the prototypical engineering vs sciences joke and is moderately humorous, but I think the fact that Wolfram has an interactive applet demonstrating the joke is funnier than the joke itself.
I recently found Lou Franco's blog post "Using Zeno's Paradox For Progress Bars" which covers the same concept as Zeno's Progress Bar but with real code. Apparently Lou wasn't making a joke and actually used this progress bar in an application. A progress bar that doesn't accurately represent progress seems dishonest. In cases like the Vista Defrag where the software can't make a reasonable guess about how long a process will take the software shouldn't display a progress bar.
Similarly a paper by Chris Harrison "Rethinking the Progress Bar" suggests that if a progress bar speeds up towards the end the user will perceive the operation as taking less time. The paper is interesting, but as in the previous case, I'd rather have progress accurately represented even if it means the user doesn't perceive the operation as being as fast.
Update: I should be clearer about Lou's post. He was actually making a practical and implementable suggestion as to how to handle the case of displaying progress when you have some idea of how long it will take but no indications of progress, whereas my suggestion is impractical and more of a joke concerning displaying progress with no indication of progress nor a general idea of how long it will take.
 This post is about creating a server side z-code
interpreter that represents game progress in the URI. Try it with the game Lost
Pig.
This post is about creating a server side z-code
interpreter that represents game progress in the URI. Try it with the game Lost
Pig.
I enjoy working on URIs and have the mug to prove it. Along those lines I've combined thoughts on URIs with interactive fiction. I have a limited amount of experience with Inform which generates Z-Code so I'll focus on pieces written in that. Of course we can already have URIs identifying the Z-Code files themselves, but I want URIs to identify my place in a piece of interactive fiction. The proper way to do this would be to give Z-Code its own mimetype and associate with that mimetype the format of a fragment that would contain the save state of user's interactive fiction session. A user would install a browser plugin that would generate URIs containing the appropriate fragment while you play the IF piece and be able to load URIs identifying Z-Code files and load the save state that appears in the fragment.
But all of that would be a lot of work, so I made a server side version that approximates this. On the Web Frotz Interpreter page, enter the URI of a Z-Code file to start a game. Enter your commands into the input text box at the bottom and you get a new URI after every command. For example, here's the beginning of Zork. I'm running a slightly modified version of the Unix version of Frotz. Baf's Guide to the IF Archive has lists of IF games to try out.
There are two issues with this thought, the first being the security issues with running arbitrary z-code and the second is the practical URI length limit of about 2K in IE. From the Z-Code standard and the Frotz source it looks like 'save' and 'restore' are the only commands that could do anything interesting outside of the Z-Code virtual machine. As for the length-limit on URIs I'm not sure that much can be done about that. I'm using a base64 encoded copy of the compressed input stream in the URI now. Switching to the actual save state might be smaller after enough user input.
 I signed up for the pre-release beta and purchased a Chumby last year. Chumby looks like a cousin to a GPS
unit. Its similar in size with a touch screen, but has WiFi, accelerometers, and is pillow like on the sides that aren't a screen. In practice its like an Internet alarm clock that shows you photos
and videos off the Web. Its hackable in that Chumby Industries tells you about the various ways to run your own stuff on the Chumby, modifying the boot sequence (it runs Linux), turning on sshd,
etc, etc. The Chumby forum too has lots of info from folks who have found interesting hacks for the device.
I signed up for the pre-release beta and purchased a Chumby last year. Chumby looks like a cousin to a GPS
unit. Its similar in size with a touch screen, but has WiFi, accelerometers, and is pillow like on the sides that aren't a screen. In practice its like an Internet alarm clock that shows you photos
and videos off the Web. Its hackable in that Chumby Industries tells you about the various ways to run your own stuff on the Chumby, modifying the boot sequence (it runs Linux), turning on sshd,
etc, etc. The Chumby forum too has lots of info from folks who have found interesting hacks for the device.
When you turn on the Chumby it downloads and runs the latest version of the Chumby software which lets you set alarms, play music, and display Flash widgets. The Chumby website lets anyone upload their own Flash widgets to share with the community. I tried my hand at creating one using Adobe's free Flash creation SDK but I don't know Flash and didn't have the patience to learn.
Currently my Chumby is set to wake me up at 8am on weekdays with music from ShoutCast and then displays traffic and weather. At 10am everyday it switches to showing me a slide-show of LolCats. At 11pm it switches to night mode where it displays the time in dark grey text on a black background at a reduced light level so as not to disturb me while I sleep.
I like the Chumby but I have two complaints. The first is that it forces me to learn flash in order to create anything cool rather than having a built-in Web browser or depending on a more Web friendly technology. The second complaint is about its name. At first I thought the name was stupid in a kind of silly way, but now that I'm used to the name it sounds vaguely dirty.






 Some rights reserved
Some rights reserved