I just upgraded to the Zune 3.0 software which includes games and purchasing music on the Zune via WiFi and once again I'm thrilled that the new firmware is available for old Zunes like mine. Rooting around looking at the new features I noticed Zune Badges for the first time. They're like Xbox Achievements, for example I have a Pixies Silver Artist Power Listener award for listening to the Pixies over 1000 times. I know its ridiculous but I like it, and now I want achievements for everything.
Achievements everywhere would require more developments in self-tracking. Self-trackers, folks who keep statistics on exactly when and what they eat, when and how much they exercise, anything one may track about one's self, were the topic of a Kevin Kelly Quantified Self blog post (also check out Cory Doctorow's SF short story The Things that Make Me Weak and Strange Get Engineered Away featuring a colony of self-trackers). For someone like me with a medium length attention span the data collection needs to be completely automatic or I will lose interest and stop collecting within a week. For instance, Nike iPod shoes that keep track of how many steps the wearer takes. I'll also need software to analyze, display, and share this data on a website like Mycrocosm. I don't want to have to spend extreme amounts of time to create something as wonderful as the Feltron Report (check out his statistic on how many daily measurements he takes for the report). Once we have the data we can give out achievements for everything!

|
Carnivore Eat at least ten different kinds of animals. |

|
Make Friends Meet at least 10% of the residents in your home town. |

|
Globetrotter Visit a city in every country. |

|
You're Old Survive at least 80 years of life. |
Of course none of the above is practical yet, but how about Delicious achievements based on the public Delicious feeds? That should be doable...
I've had a little fun messing around with Photosynth, a Microsoft research project turned into a Live service. You upload a bunch of photos from around the same area and it makes a 3D panorama out of them. For instance, here's National Geographic's photosynth of the sphinx and pyramids in Egypt. Messing around with this I've made one of half a vase of roses, and a larger photosynth of my office.

As noted previously, my page consists of the aggregation of my various feeds and in working on that code recently it was again brought to my attention that everyone has different ways of representing tag metadata in feeds. I made up a list of how my various feed sources represent tags and list that data here so that it might help others in the future.
| Source | Feed Type | Tag Markup Scheme | One Tag Per Element | Tag Scheme URI | Human / Machine Names | Example Markup |
|---|---|---|---|---|---|---|
| LiveJournal | Atom | atom:category | yes | no | no | , (source) |
| LiveJournal | RSS 2.0 | rss2:category | yes | no | no |
technical(soure) |
| WordPress | RSS 2.0 | rss2:category | yes | no | no |
, (source)
|
| Delicious | RSS 1.0 | dc:subject | no | no | no |
photosynth photos 3d tool(source) |
| Delicious | RSS 2.0 | rss2:category | yes | yes | no |
domain="http://delicious.com/SequelGuy/">(source) |
| Flickr | Atom | atom:category | yes | yes | no |
term="seattle"(source) |
| Flickr | RSS 2.0 | media:category | no | yes | no |
scheme="urn:flickr:tags">(source) |
| YouTube | RSS 2.0 | media:category | no | no | no |
label="Tags">(source) |
| LibraryThing | RSS 2.0 | No explicit tag metadata. | no | no | no | n/a, (source) |
| Tag Markup Scheme | Notes | Example |
|---|---|---|
|
Atom Category atom:category xmlns:atom="http://www.w3.org/2005/Atom"
|
|
term="catName"
|
|
RSS 2.0 category rss2:category empty namespace |
|
domain="tag:deletethis.net,2008:tagscheme">
|
|
Yahoo Media RSS Module category media:category xmlns:media="http://search.yahoo.com/mrss/"
|
|
scheme="http://dmoz.org"
|
|
Dublin Core subject dc:subject xmlns:dc="http://purl.org/dc/elements/1.1/"
|
|
humor
|
Update 2009-9-14: Added WordPress to the Tag Markup table and namespaces to the Tag Markup Scheme table.
In my Intro to Algorithms course in college the Fibonacci sequence was used as the example algorithm to which various types of algorithm creation methods were applied. As the course went on we made
better and better performing algorithms to find the nth Fibonacci number. In another course we were told about a matrix that when multiplied successively produced Fibonacci numbers. In my linear
algebra courses I realized I could diagonalize the matrix to find a non-recursive Fibonacci function. To my surprise this worked and I
found a function.
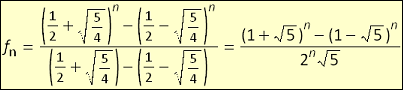
Looking online I found that of course this same function was already well known. Mostly I was irritated that after all the
algorithms we created for faster and faster Fibonacci functions we were never told about a constant time function like this.
I recently found my paper depicting this and thought it would be a good thing to use to try out MathML, a markup language for displaying math. I went to the MathML implementations page and installed a plugin for IE to display MathML and then began writing up my paper in MathML. I wrote the MathML by hand and must say that's not how its intended to be created. The language is very verbose and it took me a long time to get the page of equations transcribed.
MathML has presentation elements and content elements that can be used separately or together. I stuck to content elements and while it looked great in IE with my extension when I tried it in FireFox which has builtin MathML support it didn't render. As it turns out FireFox doesn't support MathML content elements. I had already finished creating this page by hand and wasn't about to switch to content elements. Also, in order to get IE to render a MathML document, the document needs directives at the top for specific IE extensions which is a pain. Thankfully, the W3C has a MathML cross platform stylesheet. You just include this XSL at the top of your XHTML page and it turns content elements into appropriate presentation elements, and inserts all the known IE extension goo required for you. So now my page can look lovely and all the ickiness to get it to render is contained in the W3C's XSL.
 I recently finished Braid, the Xbox Live game, and a comparison with Portal is helpful. From a screen shot Braid
looks like a normal 2D platformer, but that's like looking at a screen shot of Portal and saying its a first person shooter. While the scaffolding of the game-play may sort of fall into that
category, the games are actually about exploring the character's ability and solving puzzles. In Portal the ability is bending space and in Braid its bending time. However, whereas in Portal there
is one space bending mechanism, the portal gun, Braid's protagonist explores several different time bending techniques including, most prominently, reversing time, but also time dilation, multiple
time-lines, and other odd things.
I recently finished Braid, the Xbox Live game, and a comparison with Portal is helpful. From a screen shot Braid
looks like a normal 2D platformer, but that's like looking at a screen shot of Portal and saying its a first person shooter. While the scaffolding of the game-play may sort of fall into that
category, the games are actually about exploring the character's ability and solving puzzles. In Portal the ability is bending space and in Braid its bending time. However, whereas in Portal there
is one space bending mechanism, the portal gun, Braid's protagonist explores several different time bending techniques including, most prominently, reversing time, but also time dilation, multiple
time-lines, and other odd things.
Similar to the difference in game-play, while Portal has a strict simplicity to its visual style, Braid is much more ornate, like you're playing in an oil painting. Without seeing video of the game, or playing the demo (which is available for free on Xbox Live) its difficult to convey, but it is quite lovely and the animation adds quite a bit. Both games too are rather short leaving you just a bit hungry for more and have an interesting plot and an ending that I'd hate to spoil although Braid replaces Portal's humor with melancholy. If you enjoyed Portal and Twelve Monkeys then I'd recommend Braid.
Doctor Horrible's Sing Along Blog is an Internet only show you may have already watched and heard everything about. If you missed this somehow, its a musical by Joss Whedon (Buffy the Vampire Slayer, Firefly) staring Neil Patrick Harris as an aspiring super villian who can't get up the courage to talk to his laundromat crush. Its very funny, fairly geeky, and on the Internet so of course I've enjoyed it thoroughly and have some links to share. It surprised me how many blogs that I don't usually see posting the same things telling me about it: first on Eric's blog, then The Old New Thing, and even Penny-Arcade.
Dr. Horrible's again available online via Hulu with commercial interruption.
Check out the official fan site. They link to such things as the owner of Dr. Horrible's house. He had appeared on Monster House, a reality show about remaking people's homes like Monster Car or Pimp My Ride is about remaking folk's cars, and had his house turned into a evil scientist's lab. Consequently its a perfect fit for Dr. Horrible and in return the owner appears in one of the final scenes and in the credits as the 'Purple Pimp'. Apparently the purple suit is his. Also on his blog you can find out what's happened on that big chair that appears in the show. All I'll say about that is, good thing Neil Patrick Harris wears a lab coat while sitting on it.
At the recent Comic Con some attendees took video of the Dr. Horrible Comic Con panel (video clips contain spoilers) some of which I've grouped together. Besides the videos containing the creators and stars of the musical who are all hilarious (see Felicia Day's comment on twittering) there's also some excellent bits about a possible second installment and information on the impending DVD. To finish off this series of Dr. Horrible links check out this Venn Diagram of Felicia Day's work.

 My previous window office was ripped from me when our team moved buildings but now I've got another.
The photo is poor because I didn't get the lighting correct and it depicts the office before I've moved all my crap into it. I have a lovely view of our parking lot and freeway which Jane spun as
an 'urban view'. At any rate I'm not complaining: I like knowing what its like outside and that there is an outside. The day after I found out about my office, I also got two new patent cubes. I didn't have any pictures last time so I took some
now and blacked out their text for fear of laywers.
My previous window office was ripped from me when our team moved buildings but now I've got another.
The photo is poor because I didn't get the lighting correct and it depicts the office before I've moved all my crap into it. I have a lovely view of our parking lot and freeway which Jane spun as
an 'urban view'. At any rate I'm not complaining: I like knowing what its like outside and that there is an outside. The day after I found out about my office, I also got two new patent cubes. I didn't have any pictures last time so I took some
now and blacked out their text for fear of laywers.
 Saturday we went to Kirkland Uncorked,
a wine tasting festival near our home. We took the bus and after finding the correct one (they really should have different numbers for buses that are on the same route but traveling in different
directions) made it to the festival. Unfortunately I don't remember any of the names of the wines just which ones I enjoyed by order. Recalling that I enjoyed the first one I had and the second to
last one, doesn't really help me find them again. There were local artists who had setup booths and Sarah got
a lovely necklace. After that we ate at Cactus which, because it was such a lovely day, had all its windows and doors open.
Saturday we went to Kirkland Uncorked,
a wine tasting festival near our home. We took the bus and after finding the correct one (they really should have different numbers for buses that are on the same route but traveling in different
directions) made it to the festival. Unfortunately I don't remember any of the names of the wines just which ones I enjoyed by order. Recalling that I enjoyed the first one I had and the second to
last one, doesn't really help me find them again. There were local artists who had setup booths and Sarah got
a lovely necklace. After that we ate at Cactus which, because it was such a lovely day, had all its windows and doors open.
Sunday was quieter. A few household chores and plenty of GTA4. I almost got the One Man Army achievement but I found that after four minutes with six stars I eventually dropped back down to three stars without realizing it.
When I woke up this morning for some reason I was thinking about Polytope Tetris, my N-D Tetris game, and specifically generating Tetris pieces in various number of dimensions. When I first wrote PTT I thought that as the number of dimensions increased you could end up with an infinite number of non-equivalent crazy Tetris pieces. However this morning I realized that because you only get four blocks per piece there are only a possible three joints in a single Tetris piece which means that you only need three dimensions to represent all possible distinct N-D Tetris pieces.
Below is the table of the various possible pieces per number of dimensions and sorted by the number of joints in the piece. Notice that the 'J' and 'L' become equivalent in 3D because you can rotate the 'J' through the third dimension to make it an 'L'. The same happens for 'S' and 'Z' in 3D, and 'S+' and 'Z+' in 4D.
| Joints | Name | 1D | 2D | 3D | + |
|---|---|---|---|---|---|
| 1 | I |

|
|
|
|
| 2 | J |
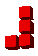
|
|
|
|
| L |
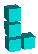
|
||||
| 3 | O |
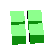
|
|
|
|
| T |

|
|
|
||
| S |

|
|
|
||
| Z |
|
||||
| T+ |

|
|
|||
| S+ |

|
|
|||
| Z+ |

|
||||
| Total | 1 | 7 | 8 | 7 |
As a consequence of not realizing there's a finite and small number of N-D Tetris pieces, I wrote code that would randomly generate pieces for a specified number of dimensions by wandering through Tetris space. This consists of first marking the current spot, then randomly picking a direction (a dimension and either forward or backward), going in that direction until hitting a previously unvisited spot and repeating until four spots are marked, forming a Tetris piece. However this morning I realized that continuing in the same direction until reaching am unvisited spot means I can't generate the 'T+' piece. I think the better way to go is keep the list of all possible pieces, pick one randomly, and rotate it randomly through the available dimensions. Doing this will also allow me to give distinct pieces their own specific color (like the classic Tetris games do) rather than picking the color randomly like I do now.
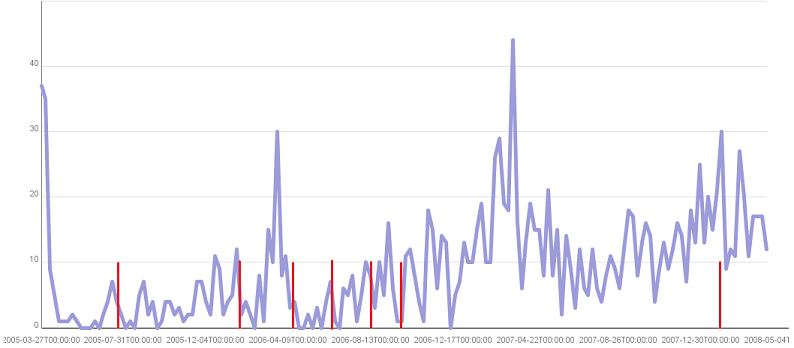
While re-reading Cryptonomicon I thought about what kind of information I'm leaking by posting links on Delicious. At work I don't post any Intranet websites for fear of revealing anything but I wondered if not posting would reveal anything. For instance, if I'm particularly busy at work might I post less indicating something about the state of the things I work on? I got an archive of my Delicious posts via the Delicious API and then ran it through a tool I made to create a couple of tables which I've graphed on Many Eyes


 Last weekend after Saul and Ciera's wedding, I drove up to Pat, Grib, and Jesse's
house to which I hadn't previously been. I got in late and they'd just finished a UFC party. The next day Grib had to travel for work but the rest of us met Scott and Nicole, Jesse's girlfriend at
a place for breakfast. After that we went back to their place for some Rock Band which I hadn't played previously and Pat took the opportunity to show off his real life musical skills on the banjo.
Last weekend after Saul and Ciera's wedding, I drove up to Pat, Grib, and Jesse's
house to which I hadn't previously been. I got in late and they'd just finished a UFC party. The next day Grib had to travel for work but the rest of us met Scott and Nicole, Jesse's girlfriend at
a place for breakfast. After that we went back to their place for some Rock Band which I hadn't played previously and Pat took the opportunity to show off his real life musical skills on the banjo.
 This weekend, Jesse and Nicole are up visiting Seattle. On Friday, Sarah and I met up with them at the BluWater Bistro in Seattle which sits right on Lake Union. The view was nice although difficult to see from our table and overall I like the sister
restaurant in Kirkland better. They were both short visits but it was fun to see people again.
This weekend, Jesse and Nicole are up visiting Seattle. On Friday, Sarah and I met up with them at the BluWater Bistro in Seattle which sits right on Lake Union. The view was nice although difficult to see from our table and overall I like the sister
restaurant in Kirkland better. They were both short visits but it was fun to see people again.
![['Neverending story' by Alexandre Duret-Lutz. A framed photo of books with the droste effect applied. Licensed under creative commons.]](http://farm1.static.flickr.com/90/252757784_3de44cbeb4_m_d.jpg) Information about URI Fragments, the portion of URIs
that follow the '#' at the end and that are used to navigate within a document, is scattered throughout various documents which I usually have to hunt down. Instead I'll link to them all here.
Information about URI Fragments, the portion of URIs
that follow the '#' at the end and that are used to navigate within a document, is scattered throughout various documents which I usually have to hunt down. Instead I'll link to them all here.
Definitions. Fragments are defined in the URI RFC which states that they're used to identify a secondary resource that is related to the primary resource identified by the URI as a subset of the primary, a view of the primary, or some other resource described by the primary. The interpretation of a fragment is based on the mime type of the primary resource. Tim Berners-Lee notes that determining fragment meaning from mime type is a problem because a single URI may contain a single fragment, however over HTTP a single URI can result in the same logical resource represented in different mime types. So there's one fragment but multiple mime types and so multiple interpretations of the one fragment. The URI RFC says that if an author has a single resource available in multiple mime types then the author must ensure that the various representations of a single resource must all resolve fragments to the same logical secondary resource. Depending on which mime types you're dealing with this is either not easy or not possible.
HTTP. In HTTP when URIs are used, the fragment is not included. The General Syntax section of the HTTP standard says it uses the definitions of 'URI-reference' (which includes the fragment), 'absoluteURI', and 'relativeURI' (which don't include the fragment) from the URI RFC. However, the 'URI-reference' term doesn't actually appear in the BNF for the protocol. Accordingly the headers like 'Request-URI', 'Content-Location', 'Location', and 'Referer' which include URIs are defined with 'absoluteURI' or 'relativeURI' and don't include the fragment. This is in keeping with the original fragment definition which says that the fragment is used as a view of the original resource and consequently only needed for resolution on the client. Additionally, the URI RFC explicitly notes that not including the fragment is a privacy feature such that page authors won't be able to stop clients from viewing whatever fragments the client chooses. This seems like an odd claim given that if the author wanted to selectively restrict access to portions of documents there are other options for them like breaking out the parts of a single resource to which the author wishes to restrict access into separate resources.
HTML. In HTML, the HTML mime type RFC defines HTML's fragment use which consists of fragments referring to elements with a corresponding 'id' attribute or one of a particular set of elements with a corresponding 'name' attribute. The HTML spec discusses fragment use additionally noting that the names and ids must be unique in the document and that they must consist of only US-ASCII characters. The ID and NAME attributes are further restricted in section 6 to only consist of alphanumerics, the hyphen, period, colon, and underscore. This is a subset of the characters allowed in the URI fragment so no encoding is discussed since technically its not needed. However, practically speaking, browsers like FireFox and Internet Explorer allow for names and ids containing characters outside of the defined set including characters that must be percent-encoded to appear in a URI fragment. The interpretation of percent-encoded characters in fragments for HTML documents is not consistent across browsers (or in some cases within the same browser) especially for the percent-encoded percent.
Text. Text/plain recently got a fragment definition that allows fragments to refer to particular lines or characters within a text document. The scheme no longer includes regular expressions, which disappointed me at first, but in retrospect is probably good idea for increasing the adoption of this fragment scheme and for avoiding the potential for ubiquitous DoS via regex. One of the authors also notes this on his blog. I look forward to the day when this scheme is widely implemented.
XML. XML has the XPointer framework to define its fragment structure as noted by the XML mime type definition. XPointer consists of a general scheme that contains subschemes that identify a subset of an XML document. Its too bad such a thing wasn't adopted for URI fragments in general to solve the problem of a single resource with multiple mime type representations. I wrote more about XPointer when I worked on hacking XPointer into IE.
SVG and MPEG. Through the Media Fragments Working Group I found a couple more fragment scheme definitions. SVG's fragment scheme is defined in the SVG documentation and looks similar to XML's. MPEG has one defined but I could only find it as an ISO document "Text of ISO/IEC FCD 21000-17 MPEG-12 FID" and not as an RFC which is a little disturbing.
AJAX. AJAX websites have used fragments as an escape hatch for two issues that I've seen. The first is getting a unique URL for versions of a page that are produced on the client by script. The fragment may be changed by script without forcing the page to reload. This goes outside the rules of the standards by using HTML fragments in a fashion not called out by the HTML spec. but it does seem to be inline with the spirit of the fragment in that it is a subview of the original resource and interpretted client side. The other hack-ier use of the fragment in AJAX is for cross domain communication. The basic idea is that different frames or windows may not communicate in normal fashions if they have different domains but they can view each other's URLs and accordingly can change their own fragments in order to send a message out to those who know where to look. IMO this is not inline with the spirit of the fragment but is rather a cool hack.
For Encode-O-Matic, my encoding tool written in C#, I had to figure out the appropriate DllImport declarations to use IDN Win32 functions which was a pain. To spare others that pain here's the two files CharacterSetEncoding.cs and NationalLanguageSupportUtilities.cs that declare the DllImports for IdnToUnicode, IdnToAscii, NormalizeString, MultiByteToWideChar, and WideCharToMultiByte.
 More of my thoughts have been stolen: In my
previous job the customer wanted a progress bar displayed while information was copied off of proprietary hardware, during which the software didn't get any indication of progress until the copy
was finished. I joked (mostly) that we could display a progress bar that continuously slows down and never quite reaches the end until we know we're done getting info from the hardware. The amount
of progress would be a function of time where as time approaches infinity, progress approaches a value of at most 100 percent.
More of my thoughts have been stolen: In my
previous job the customer wanted a progress bar displayed while information was copied off of proprietary hardware, during which the software didn't get any indication of progress until the copy
was finished. I joked (mostly) that we could display a progress bar that continuously slows down and never quite reaches the end until we know we're done getting info from the hardware. The amount
of progress would be a function of time where as time approaches infinity, progress approaches a value of at most 100 percent.
This is similar to Zeno's Paradox which says you can't cross a room because to do so first you must cross half the room, then you must cross half the remaining distance, then half the remaining again, and so on which means you must take an infinite number of steps. There's also an old joke inspired by Zeno's Paradox. The joke is the prototypical engineering vs sciences joke and is moderately humorous, but I think the fact that Wolfram has an interactive applet demonstrating the joke is funnier than the joke itself.
I recently found Lou Franco's blog post "Using Zeno's Paradox For Progress Bars" which covers the same concept as Zeno's Progress Bar but with real code. Apparently Lou wasn't making a joke and actually used this progress bar in an application. A progress bar that doesn't accurately represent progress seems dishonest. In cases like the Vista Defrag where the software can't make a reasonable guess about how long a process will take the software shouldn't display a progress bar.
Similarly a paper by Chris Harrison "Rethinking the Progress Bar" suggests that if a progress bar speeds up towards the end the user will perceive the operation as taking less time. The paper is interesting, but as in the previous case, I'd rather have progress accurately represented even if it means the user doesn't perceive the operation as being as fast.
Update: I should be clearer about Lou's post. He was actually making a practical and implementable suggestion as to how to handle the case of displaying progress when you have some idea of how long it will take but no indications of progress, whereas my suggestion is impractical and more of a joke concerning displaying progress with no indication of progress nor a general idea of how long it will take.
 I now have search and an archive available for my site. I previously tried to setup crappy search by cheating using Yahoo Pipes and now
instead I have a slightly less crappy search that works over all of the content that I've produced on my blog, uploaded to flickr or youtube, or added to delicious.
I now have search and an archive available for my site. I previously tried to setup crappy search by cheating using Yahoo Pipes and now
instead I have a slightly less crappy search that works over all of the content that I've produced on my blog, uploaded to flickr or youtube, or added to delicious.
You can now read my first LiveJournal blog post or, for probably much more entertainment value, view all the photos and videos of Cadbury by searching for 'bunny'.
The search is only slightly less lame because although it searches over all my content, I still implemented it myself rather than getting a professional package. Also, the feed supports the same search and archive as my homepage so you can subscribe to a feed of Cadbury if you're so inclined and just skip all this other boring stuff. My homepage and feed implement the OpenSearch response elements and I've got an OpenSearch search provider (source) as well.




 Some rights reserved
Some rights reserved