 The weekend before last was Sarah's birthday and as part of
that, last weekend we took a trip to Victoria, BC. I've got a map of our trip locations and photos. Not all the
photos are on the map but they're all in the trip photo set on Flickr. It turns out there's a lot of tourist intended
activities right around our hotel which was in the inner harbor and downtown Victoria area. As such we didn't get a rental car and did a lot of walking.
The weekend before last was Sarah's birthday and as part of
that, last weekend we took a trip to Victoria, BC. I've got a map of our trip locations and photos. Not all the
photos are on the map but they're all in the trip photo set on Flickr. It turns out there's a lot of tourist intended
activities right around our hotel which was in the inner harbor and downtown Victoria area. As such we didn't get a rental car and did a lot of walking.
 On the first day we checked out the Royal British Columbia Museum which had
some interesting exhibits in it and the Undersea Garden which was interesting in that its like a floating aquarium but was a bit grimy. There was a group of Japanese tourists next to us during the
undersea show in which a diver behind the glass in the ocean would pick up and parade various animal life. The group all repeated the word starfish in unison after the show's narrator and one of
the tourists was very excited to see the diver bring over the octopus. The diver made the octopus wave to us while it desperately tried to get away.
On the first day we checked out the Royal British Columbia Museum which had
some interesting exhibits in it and the Undersea Garden which was interesting in that its like a floating aquarium but was a bit grimy. There was a group of Japanese tourists next to us during the
undersea show in which a diver behind the glass in the ocean would pick up and parade various animal life. The group all repeated the word starfish in unison after the show's narrator and one of
the tourists was very excited to see the diver bring over the octopus. The diver made the octopus wave to us while it desperately tried to get away.
 We flew in and out of the Victoria International Airport
which is a smaller sized airport. Although we needed our passports we didn't need to take off our shoes -- what convenience! The US dollar was just a bit worse than the Canadian dollar which was
also convenient. The weather was lovely while we were there and I only got slightly sun burned.
We flew in and out of the Victoria International Airport
which is a smaller sized airport. Although we needed our passports we didn't need to take off our shoes -- what convenience! The US dollar was just a bit worse than the Canadian dollar which was
also convenient. The weather was lovely while we were there and I only got slightly sun burned.
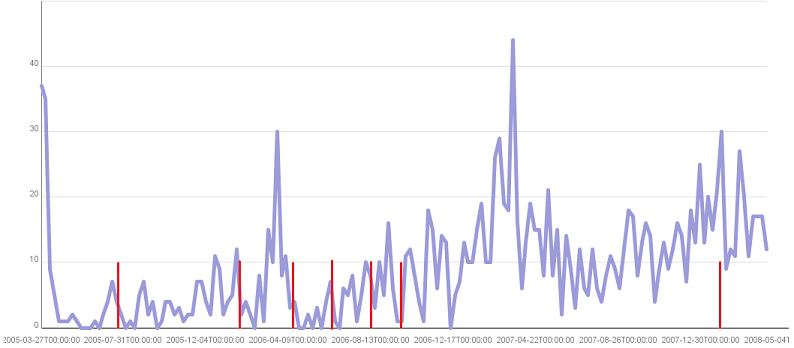
While re-reading Cryptonomicon I thought about what kind of information I'm leaking by posting links on Delicious. At work I don't post any Intranet websites for fear of revealing anything but I wondered if not posting would reveal anything. For instance, if I'm particularly busy at work might I post less indicating something about the state of the things I work on? I got an archive of my Delicious posts via the Delicious API and then ran it through a tool I made to create a couple of tables which I've graphed on Many Eyes


![[sprague's photo of Corteo in Maryland]](http://farm3.static.flickr.com/2322/2465010137_9e6f945bb0_t_d.jpg) Sarah and I went to Cirque du
Soleil's Corteo this past Wednesday. Its in Marymoor Park quite near the main Microsoft campus. They setup
large circus tents in the park including a gift shop, overpriced concession stands, and long lined porta-potties. Despite all this the show was very entertaining and quite enjoyable. The show is
like a circus directed by Terry Gilliam or Tim Schafer and otherwise I'm not sure how to describe it, but I do recommend it.
Sarah and I went to Cirque du
Soleil's Corteo this past Wednesday. Its in Marymoor Park quite near the main Microsoft campus. They setup
large circus tents in the park including a gift shop, overpriced concession stands, and long lined porta-potties. Despite all this the show was very entertaining and quite enjoyable. The show is
like a circus directed by Terry Gilliam or Tim Schafer and otherwise I'm not sure how to describe it, but I do recommend it.
 Last weekend while Sarah was up in Canada for a spa weekend with her sister and her sister's other bridesmaids, I went to Saul and Ciera's
wedding in Three Rivers, California near Sequoia National Park. I flew into Fresno picked up a rental car and my GPS device navigated me to a restaurant with the wedding location no where in sight.
"No problem," I thought, "I'll just call someone with an Internet connection and..." I had no cell reception. What did people do before GPS, Internet, and cell phones?
Last weekend while Sarah was up in Canada for a spa weekend with her sister and her sister's other bridesmaids, I went to Saul and Ciera's
wedding in Three Rivers, California near Sequoia National Park. I flew into Fresno picked up a rental car and my GPS device navigated me to a restaurant with the wedding location no where in sight.
"No problem," I thought, "I'll just call someone with an Internet connection and..." I had no cell reception. What did people do before GPS, Internet, and cell phones?
 A waitress in the restaurant pointed me down the road a bit to the wedding location which was outside overlooking a
river. Their wedding cake was made up like a mountain with two backpacks at the top and rope hanging down. Ciera's father married them and the ceremony was lovely. The music after included Code Monkey to which all the nerds were forced to get up and awkwardly dance.
A waitress in the restaurant pointed me down the road a bit to the wedding location which was outside overlooking a
river. Their wedding cake was made up like a mountain with two backpacks at the top and rope hanging down. Ciera's father married them and the ceremony was lovely. The music after included Code Monkey to which all the nerds were forced to get up and awkwardly dance.
 Besides getting to see Ciera and Saul who I hadn't seen in quite a while, I got to see Daniil and Val, Vlad, and Nathaniel. Since
last I saw Daniil and Val they had a child, Katie who is very cute and in whom I can see a lot of family resemblance. The always hilarious Vlad,
Daniil's brother, was there as well with his wife who I got to meet. Nathaniel, my manager from Vizolutions was there and I don't know if I've seen him since I moved to Washington. It was fun to
see him and meet his girlfriend who was kind enough to donate her extra male to male mini-phono cord so I could listen to my Zune in the rental car stereo on the drive back.
Besides getting to see Ciera and Saul who I hadn't seen in quite a while, I got to see Daniil and Val, Vlad, and Nathaniel. Since
last I saw Daniil and Val they had a child, Katie who is very cute and in whom I can see a lot of family resemblance. The always hilarious Vlad,
Daniil's brother, was there as well with his wife who I got to meet. Nathaniel, my manager from Vizolutions was there and I don't know if I've seen him since I moved to Washington. It was fun to
see him and meet his girlfriend who was kind enough to donate her extra male to male mini-phono cord so I could listen to my Zune in the rental car stereo on the drive back.
![['Neverending story' by Alexandre Duret-Lutz. A framed photo of books with the droste effect applied. Licensed under creative commons.]](http://farm1.static.flickr.com/90/252757784_3de44cbeb4_m_d.jpg) Information about URI Fragments, the portion of URIs
that follow the '#' at the end and that are used to navigate within a document, is scattered throughout various documents which I usually have to hunt down. Instead I'll link to them all here.
Information about URI Fragments, the portion of URIs
that follow the '#' at the end and that are used to navigate within a document, is scattered throughout various documents which I usually have to hunt down. Instead I'll link to them all here.
Definitions. Fragments are defined in the URI RFC which states that they're used to identify a secondary resource that is related to the primary resource identified by the URI as a subset of the primary, a view of the primary, or some other resource described by the primary. The interpretation of a fragment is based on the mime type of the primary resource. Tim Berners-Lee notes that determining fragment meaning from mime type is a problem because a single URI may contain a single fragment, however over HTTP a single URI can result in the same logical resource represented in different mime types. So there's one fragment but multiple mime types and so multiple interpretations of the one fragment. The URI RFC says that if an author has a single resource available in multiple mime types then the author must ensure that the various representations of a single resource must all resolve fragments to the same logical secondary resource. Depending on which mime types you're dealing with this is either not easy or not possible.
HTTP. In HTTP when URIs are used, the fragment is not included. The General Syntax section of the HTTP standard says it uses the definitions of 'URI-reference' (which includes the fragment), 'absoluteURI', and 'relativeURI' (which don't include the fragment) from the URI RFC. However, the 'URI-reference' term doesn't actually appear in the BNF for the protocol. Accordingly the headers like 'Request-URI', 'Content-Location', 'Location', and 'Referer' which include URIs are defined with 'absoluteURI' or 'relativeURI' and don't include the fragment. This is in keeping with the original fragment definition which says that the fragment is used as a view of the original resource and consequently only needed for resolution on the client. Additionally, the URI RFC explicitly notes that not including the fragment is a privacy feature such that page authors won't be able to stop clients from viewing whatever fragments the client chooses. This seems like an odd claim given that if the author wanted to selectively restrict access to portions of documents there are other options for them like breaking out the parts of a single resource to which the author wishes to restrict access into separate resources.
HTML. In HTML, the HTML mime type RFC defines HTML's fragment use which consists of fragments referring to elements with a corresponding 'id' attribute or one of a particular set of elements with a corresponding 'name' attribute. The HTML spec discusses fragment use additionally noting that the names and ids must be unique in the document and that they must consist of only US-ASCII characters. The ID and NAME attributes are further restricted in section 6 to only consist of alphanumerics, the hyphen, period, colon, and underscore. This is a subset of the characters allowed in the URI fragment so no encoding is discussed since technically its not needed. However, practically speaking, browsers like FireFox and Internet Explorer allow for names and ids containing characters outside of the defined set including characters that must be percent-encoded to appear in a URI fragment. The interpretation of percent-encoded characters in fragments for HTML documents is not consistent across browsers (or in some cases within the same browser) especially for the percent-encoded percent.
Text. Text/plain recently got a fragment definition that allows fragments to refer to particular lines or characters within a text document. The scheme no longer includes regular expressions, which disappointed me at first, but in retrospect is probably good idea for increasing the adoption of this fragment scheme and for avoiding the potential for ubiquitous DoS via regex. One of the authors also notes this on his blog. I look forward to the day when this scheme is widely implemented.
XML. XML has the XPointer framework to define its fragment structure as noted by the XML mime type definition. XPointer consists of a general scheme that contains subschemes that identify a subset of an XML document. Its too bad such a thing wasn't adopted for URI fragments in general to solve the problem of a single resource with multiple mime type representations. I wrote more about XPointer when I worked on hacking XPointer into IE.
SVG and MPEG. Through the Media Fragments Working Group I found a couple more fragment scheme definitions. SVG's fragment scheme is defined in the SVG documentation and looks similar to XML's. MPEG has one defined but I could only find it as an ISO document "Text of ISO/IEC FCD 21000-17 MPEG-12 FID" and not as an RFC which is a little disturbing.
AJAX. AJAX websites have used fragments as an escape hatch for two issues that I've seen. The first is getting a unique URL for versions of a page that are produced on the client by script. The fragment may be changed by script without forcing the page to reload. This goes outside the rules of the standards by using HTML fragments in a fashion not called out by the HTML spec. but it does seem to be inline with the spirit of the fragment in that it is a subview of the original resource and interpretted client side. The other hack-ier use of the fragment in AJAX is for cross domain communication. The basic idea is that different frames or windows may not communicate in normal fashions if they have different domains but they can view each other's URLs and accordingly can change their own fragments in order to send a message out to those who know where to look. IMO this is not inline with the spirit of the fragment but is rather a cool hack.
 It was warm and lovely out this past Saturday and Sarah I and went to a
new place for lunch, then to Kelsey Creek Park, and then out for Jane's birthday. We ate at Cafe
Pirouette which serves crepes and is done up with French decorations reminding me of my parent's house. We got in for just the end of lunch and saw the second to last customers, a gaggle of
older ladies leaving. I felt a little out of place with my "Longhorn [heart] RSS" t-shirt on. The food was good and in larger portions that I expected.
It was warm and lovely out this past Saturday and Sarah I and went to a
new place for lunch, then to Kelsey Creek Park, and then out for Jane's birthday. We ate at Cafe
Pirouette which serves crepes and is done up with French decorations reminding me of my parent's house. We got in for just the end of lunch and saw the second to last customers, a gaggle of
older ladies leaving. I felt a little out of place with my "Longhorn [heart] RSS" t-shirt on. The food was good and in larger portions that I expected.
 After that we went to Kelsey Creek Park and Farm. The park is hidden at the end of a quiet neighborhood, starts out with some tables and children's jungle gym
equipment, then there's a farm which includes a petting zoo, followed by many little trails going off into the forrest. There weren't too many animals out and the ones we did see didn't seem to
expect or want the sun and warm weather. We followed one of the trails for a bit and turned back before getting sun burned. You can see
my weekend photos mapped out on Live Maps.
After that we went to Kelsey Creek Park and Farm. The park is hidden at the end of a quiet neighborhood, starts out with some tables and children's jungle gym
equipment, then there's a farm which includes a petting zoo, followed by many little trails going off into the forrest. There weren't too many animals out and the ones we did see didn't seem to
expect or want the sun and warm weather. We followed one of the trails for a bit and turned back before getting sun burned. You can see
my weekend photos mapped out on Live Maps.
That night we went out with some friends for Jane's birthday. Eric was just back from the RSA conference and we met Jane and Eric and others at Palace Kitchen in Seattle located immediately adjascent to the monorail's route. The weather was still good so they left the large windows open through twilight and every so often you'd see the monorail pass by.
 More of my thoughts have been stolen: In my
previous job the customer wanted a progress bar displayed while information was copied off of proprietary hardware, during which the software didn't get any indication of progress until the copy
was finished. I joked (mostly) that we could display a progress bar that continuously slows down and never quite reaches the end until we know we're done getting info from the hardware. The amount
of progress would be a function of time where as time approaches infinity, progress approaches a value of at most 100 percent.
More of my thoughts have been stolen: In my
previous job the customer wanted a progress bar displayed while information was copied off of proprietary hardware, during which the software didn't get any indication of progress until the copy
was finished. I joked (mostly) that we could display a progress bar that continuously slows down and never quite reaches the end until we know we're done getting info from the hardware. The amount
of progress would be a function of time where as time approaches infinity, progress approaches a value of at most 100 percent.
This is similar to Zeno's Paradox which says you can't cross a room because to do so first you must cross half the room, then you must cross half the remaining distance, then half the remaining again, and so on which means you must take an infinite number of steps. There's also an old joke inspired by Zeno's Paradox. The joke is the prototypical engineering vs sciences joke and is moderately humorous, but I think the fact that Wolfram has an interactive applet demonstrating the joke is funnier than the joke itself.
I recently found Lou Franco's blog post "Using Zeno's Paradox For Progress Bars" which covers the same concept as Zeno's Progress Bar but with real code. Apparently Lou wasn't making a joke and actually used this progress bar in an application. A progress bar that doesn't accurately represent progress seems dishonest. In cases like the Vista Defrag where the software can't make a reasonable guess about how long a process will take the software shouldn't display a progress bar.
Similarly a paper by Chris Harrison "Rethinking the Progress Bar" suggests that if a progress bar speeds up towards the end the user will perceive the operation as taking less time. The paper is interesting, but as in the previous case, I'd rather have progress accurately represented even if it means the user doesn't perceive the operation as being as fast.
Update: I should be clearer about Lou's post. He was actually making a practical and implementable suggestion as to how to handle the case of displaying progress when you have some idea of how long it will take but no indications of progress, whereas my suggestion is impractical and more of a joke concerning displaying progress with no indication of progress nor a general idea of how long it will take.
 I now have search and an archive available for my site. I previously tried to setup crappy search by cheating using Yahoo Pipes and now
instead I have a slightly less crappy search that works over all of the content that I've produced on my blog, uploaded to flickr or youtube, or added to delicious.
I now have search and an archive available for my site. I previously tried to setup crappy search by cheating using Yahoo Pipes and now
instead I have a slightly less crappy search that works over all of the content that I've produced on my blog, uploaded to flickr or youtube, or added to delicious.
You can now read my first LiveJournal blog post or, for probably much more entertainment value, view all the photos and videos of Cadbury by searching for 'bunny'.
The search is only slightly less lame because although it searches over all my content, I still implemented it myself rather than getting a professional package. Also, the feed supports the same search and archive as my homepage so you can subscribe to a feed of Cadbury if you're so inclined and just skip all this other boring stuff. My homepage and feed implement the OpenSearch response elements and I've got an OpenSearch search provider (source) as well.
 I ordered a ThinkGeek Bluetooth Retro Handset to use at home. When I come home I plug my phone in to charge in my room, but then I can't hear it ring
elsewhere in the hosue. The idea was to take this handset which wirelessly connects to cellphones via bluetooth and place it in another part of the house so that I can tell I'm getting an incoming
call. The only issue I have with that setup is that it ringing isn't any louder than conversations held over the phone, that is, the ringing is a little quiet.
I ordered a ThinkGeek Bluetooth Retro Handset to use at home. When I come home I plug my phone in to charge in my room, but then I can't hear it ring
elsewhere in the hosue. The idea was to take this handset which wirelessly connects to cellphones via bluetooth and place it in another part of the house so that I can tell I'm getting an incoming
call. The only issue I have with that setup is that it ringing isn't any louder than conversations held over the phone, that is, the ringing is a little quiet.
The handset pairs with cellphones in the same manner as any other handset over bluetooth. It has an internal rechargeable battery which is charged via a standard USB port built into the base of the handset and it comes with a USB cable. Next to the USB port is the only button on the phone which is pressed to answer a call, hang up a call, or begin voice dial, held down to turn the handset on and off, and held down longer to begin pairing with a cellphone. There's a blue LED in one of the holes in the microphone portion of the phone which blinks to indicate if its on or trying to pair. Transitioning between on, off, and pairing produces a cute sound and a change to the LED.
Overal I'm pleased with its simplicity and use of common parts although I wish there was a way to adjust the volume of the ring.




 Some rights reserved
Some rights reserved