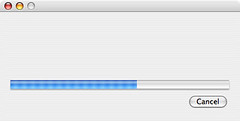
 More of my thoughts have been stolen: In my
previous job the customer wanted a progress bar displayed while information was copied off of proprietary hardware, during which the software didn't get any indication of progress until the copy
was finished. I joked (mostly) that we could display a progress bar that continuously slows down and never quite reaches the end until we know we're done getting info from the hardware. The amount
of progress would be a function of time where as time approaches infinity, progress approaches a value of at most 100 percent.
More of my thoughts have been stolen: In my
previous job the customer wanted a progress bar displayed while information was copied off of proprietary hardware, during which the software didn't get any indication of progress until the copy
was finished. I joked (mostly) that we could display a progress bar that continuously slows down and never quite reaches the end until we know we're done getting info from the hardware. The amount
of progress would be a function of time where as time approaches infinity, progress approaches a value of at most 100 percent.
This is similar to Zeno's Paradox which says you can't cross a room because to do so first you must cross half the room, then you must cross half the remaining distance, then half the remaining again, and so on which means you must take an infinite number of steps. There's also an old joke inspired by Zeno's Paradox. The joke is the prototypical engineering vs sciences joke and is moderately humorous, but I think the fact that Wolfram has an interactive applet demonstrating the joke is funnier than the joke itself.
I recently found Lou Franco's blog post "Using Zeno's Paradox For Progress Bars" which covers the same concept as Zeno's Progress Bar but with real code. Apparently Lou wasn't making a joke and actually used this progress bar in an application. A progress bar that doesn't accurately represent progress seems dishonest. In cases like the Vista Defrag where the software can't make a reasonable guess about how long a process will take the software shouldn't display a progress bar.
Similarly a paper by Chris Harrison "Rethinking the Progress Bar" suggests that if a progress bar speeds up towards the end the user will perceive the operation as taking less time. The paper is interesting, but as in the previous case, I'd rather have progress accurately represented even if it means the user doesn't perceive the operation as being as fast.
Update: I should be clearer about Lou's post. He was actually making a practical and implementable suggestion as to how to handle the case of displaying progress when you have some idea of how long it will take but no indications of progress, whereas my suggestion is impractical and more of a joke concerning displaying progress with no indication of progress nor a general idea of how long it will take.
 I now have search and an archive available for my site. I previously tried to setup crappy search by cheating using Yahoo Pipes and now
instead I have a slightly less crappy search that works over all of the content that I've produced on my blog, uploaded to flickr or youtube, or added to delicious.
I now have search and an archive available for my site. I previously tried to setup crappy search by cheating using Yahoo Pipes and now
instead I have a slightly less crappy search that works over all of the content that I've produced on my blog, uploaded to flickr or youtube, or added to delicious.
You can now read my first LiveJournal blog post or, for probably much more entertainment value, view all the photos and videos of Cadbury by searching for 'bunny'.
The search is only slightly less lame because although it searches over all my content, I still implemented it myself rather than getting a professional package. Also, the feed supports the same search and archive as my homepage so you can subscribe to a feed of Cadbury if you're so inclined and just skip all this other boring stuff. My homepage and feed implement the OpenSearch response elements and I've got an OpenSearch search provider (source) as well.

 With the new features of IE8 there's several easy ways to integrate Gmail, Google's web mail service, for mail composition, searching, and monitoring that I enjoy using.
With the new features of IE8 there's several easy ways to integrate Gmail, Google's web mail service, for mail composition, searching, and monitoring that I enjoy using.
 Two weekends ago it was actually sunny and kind of warm so Sarah and I went down to Spud Fish and Chips and Juanita Beach Park. We ate fish and chips on the dock. I took a few pictures and this
time actually put some geographical information on Flickr so now I've got a map of my tiny fish and chips journey. On the map click on the floating marks to view the associated photos.
Two weekends ago it was actually sunny and kind of warm so Sarah and I went down to Spud Fish and Chips and Juanita Beach Park. We ate fish and chips on the dock. I took a few pictures and this
time actually put some geographical information on Flickr so now I've got a map of my tiny fish and chips journey. On the map click on the floating marks to view the associated photos.
Flickr provides access to the geo data associated with your photos via GeoRSS feeds. And Google Maps displays GeoRSS feed content on their maps allowing you even to edit the data but doesn't appear to let you easily export the GeoRSS. Live Maps does the inverse, allowing you to create and export GeoRSS data but not import it. I'd like both please. Oh well.
 This post is about creating a server side z-code
interpreter that represents game progress in the URI. Try it with the game Lost
Pig.
This post is about creating a server side z-code
interpreter that represents game progress in the URI. Try it with the game Lost
Pig.
I enjoy working on URIs and have the mug to prove it. Along those lines I've combined thoughts on URIs with interactive fiction. I have a limited amount of experience with Inform which generates Z-Code so I'll focus on pieces written in that. Of course we can already have URIs identifying the Z-Code files themselves, but I want URIs to identify my place in a piece of interactive fiction. The proper way to do this would be to give Z-Code its own mimetype and associate with that mimetype the format of a fragment that would contain the save state of user's interactive fiction session. A user would install a browser plugin that would generate URIs containing the appropriate fragment while you play the IF piece and be able to load URIs identifying Z-Code files and load the save state that appears in the fragment.
But all of that would be a lot of work, so I made a server side version that approximates this. On the Web Frotz Interpreter page, enter the URI of a Z-Code file to start a game. Enter your commands into the input text box at the bottom and you get a new URI after every command. For example, here's the beginning of Zork. I'm running a slightly modified version of the Unix version of Frotz. Baf's Guide to the IF Archive has lists of IF games to try out.
There are two issues with this thought, the first being the security issues with running arbitrary z-code and the second is the practical URI length limit of about 2K in IE. From the Z-Code standard and the Frotz source it looks like 'save' and 'restore' are the only commands that could do anything interesting outside of the Z-Code virtual machine. As for the length-limit on URIs I'm not sure that much can be done about that. I'm using a base64 encoded copy of the compressed input stream in the URI now. Switching to the actual save state might be smaller after enough user input.
 I signed up for the pre-release beta and purchased a Chumby last year. Chumby looks like a cousin to a GPS
unit. Its similar in size with a touch screen, but has WiFi, accelerometers, and is pillow like on the sides that aren't a screen. In practice its like an Internet alarm clock that shows you photos
and videos off the Web. Its hackable in that Chumby Industries tells you about the various ways to run your own stuff on the Chumby, modifying the boot sequence (it runs Linux), turning on sshd,
etc, etc. The Chumby forum too has lots of info from folks who have found interesting hacks for the device.
I signed up for the pre-release beta and purchased a Chumby last year. Chumby looks like a cousin to a GPS
unit. Its similar in size with a touch screen, but has WiFi, accelerometers, and is pillow like on the sides that aren't a screen. In practice its like an Internet alarm clock that shows you photos
and videos off the Web. Its hackable in that Chumby Industries tells you about the various ways to run your own stuff on the Chumby, modifying the boot sequence (it runs Linux), turning on sshd,
etc, etc. The Chumby forum too has lots of info from folks who have found interesting hacks for the device.
When you turn on the Chumby it downloads and runs the latest version of the Chumby software which lets you set alarms, play music, and display Flash widgets. The Chumby website lets anyone upload their own Flash widgets to share with the community. I tried my hand at creating one using Adobe's free Flash creation SDK but I don't know Flash and didn't have the patience to learn.
Currently my Chumby is set to wake me up at 8am on weekdays with music from ShoutCast and then displays traffic and weather. At 10am everyday it switches to showing me a slide-show of LolCats. At 11pm it switches to night mode where it displays the time in dark grey text on a black background at a reduced light level so as not to disturb me while I sleep.
I like the Chumby but I have two complaints. The first is that it forces me to learn flash in order to create anything cool rather than having a built-in Web browser or depending on a more Web friendly technology. The second complaint is about its name. At first I thought the name was stupid in a kind of silly way, but now that I'm used to the name it sounds vaguely dirty.
 I got a FlickrMail from Emma J. Williams a bit ago saying that they wanted to
use two of my photos in their Schmap San Francisco Guide online travel guide. So now you can see two of my vacation photos on the Westfield San Francisco Shopping Center Schmap page and the Hotel Diva Schmap page.
I got a FlickrMail from Emma J. Williams a bit ago saying that they wanted to
use two of my photos in their Schmap San Francisco Guide online travel guide. So now you can see two of my vacation photos on the Westfield San Francisco Shopping Center Schmap page and the Hotel Diva Schmap page.
 I think its wonderful that digital cameras are at
the point where I really don't have to know much about their workings to produce a photo that's reasonable looking. And its thanks to Flickr and searchable tags that Schmap could find my photos.
Since my photos on Flickr are all licensed under a Creative Commons license named Attribution-Noncommercial-No Derivative Works
2.0 Generic which only applies to non-commercial uses, Schmap, which is advertisement supported, kindly asked me if they could use my photos. I agreed to their license which was human readable
and included wonderful stuff like I get in place attribution and the license is only applicable while Schmap makes their guide freely available online.
I think its wonderful that digital cameras are at
the point where I really don't have to know much about their workings to produce a photo that's reasonable looking. And its thanks to Flickr and searchable tags that Schmap could find my photos.
Since my photos on Flickr are all licensed under a Creative Commons license named Attribution-Noncommercial-No Derivative Works
2.0 Generic which only applies to non-commercial uses, Schmap, which is advertisement supported, kindly asked me if they could use my photos. I agreed to their license which was human readable
and included wonderful stuff like I get in place attribution and the license is only applicable while Schmap makes their guide freely available online.
Previously I've only heard of folks having their flickr photos used without their permission so I'm glad to know that's not always the case. Or perhaps this is just Schmap's clever method of getting me to blog about them.






 Some rights reserved
Some rights reserved{kind=link}
{kind=link}