I've had a little fun messing around with Photosynth, a Microsoft research project turned into a Live service. You upload a bunch of photos from around the same area and it makes a 3D panorama out of them. For instance, here's National Geographic's photosynth of the sphinx and pyramids in Egypt. Messing around with this I've made one of half a vase of roses, and a larger photosynth of my office.

In my Intro to Algorithms course in college the Fibonacci sequence was used as the example algorithm to which various types of algorithm creation methods were applied. As the course went on we made
better and better performing algorithms to find the nth Fibonacci number. In another course we were told about a matrix that when multiplied successively produced Fibonacci numbers. In my linear
algebra courses I realized I could diagonalize the matrix to find a non-recursive Fibonacci function. To my surprise this worked and I
found a function.
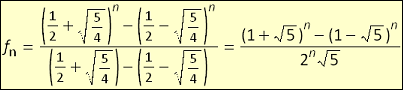
Looking online I found that of course this same function was already well known. Mostly I was irritated that after all the
algorithms we created for faster and faster Fibonacci functions we were never told about a constant time function like this.
I recently found my paper depicting this and thought it would be a good thing to use to try out MathML, a markup language for displaying math. I went to the MathML implementations page and installed a plugin for IE to display MathML and then began writing up my paper in MathML. I wrote the MathML by hand and must say that's not how its intended to be created. The language is very verbose and it took me a long time to get the page of equations transcribed.
MathML has presentation elements and content elements that can be used separately or together. I stuck to content elements and while it looked great in IE with my extension when I tried it in FireFox which has builtin MathML support it didn't render. As it turns out FireFox doesn't support MathML content elements. I had already finished creating this page by hand and wasn't about to switch to content elements. Also, in order to get IE to render a MathML document, the document needs directives at the top for specific IE extensions which is a pain. Thankfully, the W3C has a MathML cross platform stylesheet. You just include this XSL at the top of your XHTML page and it turns content elements into appropriate presentation elements, and inserts all the known IE extension goo required for you. So now my page can look lovely and all the ickiness to get it to render is contained in the W3C's XSL.
Doctor Horrible's Sing Along Blog is an Internet only show you may have already watched and heard everything about. If you missed this somehow, its a musical by Joss Whedon (Buffy the Vampire Slayer, Firefly) staring Neil Patrick Harris as an aspiring super villian who can't get up the courage to talk to his laundromat crush. Its very funny, fairly geeky, and on the Internet so of course I've enjoyed it thoroughly and have some links to share. It surprised me how many blogs that I don't usually see posting the same things telling me about it: first on Eric's blog, then The Old New Thing, and even Penny-Arcade.
Dr. Horrible's again available online via Hulu with commercial interruption.
Check out the official fan site. They link to such things as the owner of Dr. Horrible's house. He had appeared on Monster House, a reality show about remaking people's homes like Monster Car or Pimp My Ride is about remaking folk's cars, and had his house turned into a evil scientist's lab. Consequently its a perfect fit for Dr. Horrible and in return the owner appears in one of the final scenes and in the credits as the 'Purple Pimp'. Apparently the purple suit is his. Also on his blog you can find out what's happened on that big chair that appears in the show. All I'll say about that is, good thing Neil Patrick Harris wears a lab coat while sitting on it.
At the recent Comic Con some attendees took video of the Dr. Horrible Comic Con panel (video clips contain spoilers) some of which I've grouped together. Besides the videos containing the creators and stars of the musical who are all hilarious (see Felicia Day's comment on twittering) there's also some excellent bits about a possible second installment and information on the impending DVD. To finish off this series of Dr. Horrible links check out this Venn Diagram of Felicia Day's work.
Sarah and I saw the Kids in the Hall "Live As We'll Ever Be" Tour in the WaMu theater in Seattle this past Thursday. I'd only ever seen their television show so it was cool to see them live. I thought that them being in a live format on stage would make the show significantly different, but other than having a bad seat and not being able to see very well, and the Kids sometimes ad-libbing or breaking character, it was like watching their show. It consisted of mostly new material with some returning characters like the Chicken Lady, Buddy Cole, the head crusher, etc. Their Facebook page has two videos that they played during the show.
I've been using the best Kids in the Hall fansite with an archive of searchable transcripts since high school. But now days what with all the new fangled video websites I can link right to some of my favorite sketches from the show. Like the Inexperienced Cannibal.
And the meta-sketch The Raise.
![['Neverending story' by Alexandre Duret-Lutz. A framed photo of books with the droste effect applied. Licensed under creative commons.]](http://farm1.static.flickr.com/90/252757784_3de44cbeb4_m_d.jpg) Information about URI Fragments, the portion of URIs
that follow the '#' at the end and that are used to navigate within a document, is scattered throughout various documents which I usually have to hunt down. Instead I'll link to them all here.
Information about URI Fragments, the portion of URIs
that follow the '#' at the end and that are used to navigate within a document, is scattered throughout various documents which I usually have to hunt down. Instead I'll link to them all here.
Definitions. Fragments are defined in the URI RFC which states that they're used to identify a secondary resource that is related to the primary resource identified by the URI as a subset of the primary, a view of the primary, or some other resource described by the primary. The interpretation of a fragment is based on the mime type of the primary resource. Tim Berners-Lee notes that determining fragment meaning from mime type is a problem because a single URI may contain a single fragment, however over HTTP a single URI can result in the same logical resource represented in different mime types. So there's one fragment but multiple mime types and so multiple interpretations of the one fragment. The URI RFC says that if an author has a single resource available in multiple mime types then the author must ensure that the various representations of a single resource must all resolve fragments to the same logical secondary resource. Depending on which mime types you're dealing with this is either not easy or not possible.
HTTP. In HTTP when URIs are used, the fragment is not included. The General Syntax section of the HTTP standard says it uses the definitions of 'URI-reference' (which includes the fragment), 'absoluteURI', and 'relativeURI' (which don't include the fragment) from the URI RFC. However, the 'URI-reference' term doesn't actually appear in the BNF for the protocol. Accordingly the headers like 'Request-URI', 'Content-Location', 'Location', and 'Referer' which include URIs are defined with 'absoluteURI' or 'relativeURI' and don't include the fragment. This is in keeping with the original fragment definition which says that the fragment is used as a view of the original resource and consequently only needed for resolution on the client. Additionally, the URI RFC explicitly notes that not including the fragment is a privacy feature such that page authors won't be able to stop clients from viewing whatever fragments the client chooses. This seems like an odd claim given that if the author wanted to selectively restrict access to portions of documents there are other options for them like breaking out the parts of a single resource to which the author wishes to restrict access into separate resources.
HTML. In HTML, the HTML mime type RFC defines HTML's fragment use which consists of fragments referring to elements with a corresponding 'id' attribute or one of a particular set of elements with a corresponding 'name' attribute. The HTML spec discusses fragment use additionally noting that the names and ids must be unique in the document and that they must consist of only US-ASCII characters. The ID and NAME attributes are further restricted in section 6 to only consist of alphanumerics, the hyphen, period, colon, and underscore. This is a subset of the characters allowed in the URI fragment so no encoding is discussed since technically its not needed. However, practically speaking, browsers like FireFox and Internet Explorer allow for names and ids containing characters outside of the defined set including characters that must be percent-encoded to appear in a URI fragment. The interpretation of percent-encoded characters in fragments for HTML documents is not consistent across browsers (or in some cases within the same browser) especially for the percent-encoded percent.
Text. Text/plain recently got a fragment definition that allows fragments to refer to particular lines or characters within a text document. The scheme no longer includes regular expressions, which disappointed me at first, but in retrospect is probably good idea for increasing the adoption of this fragment scheme and for avoiding the potential for ubiquitous DoS via regex. One of the authors also notes this on his blog. I look forward to the day when this scheme is widely implemented.
XML. XML has the XPointer framework to define its fragment structure as noted by the XML mime type definition. XPointer consists of a general scheme that contains subschemes that identify a subset of an XML document. Its too bad such a thing wasn't adopted for URI fragments in general to solve the problem of a single resource with multiple mime type representations. I wrote more about XPointer when I worked on hacking XPointer into IE.
SVG and MPEG. Through the Media Fragments Working Group I found a couple more fragment scheme definitions. SVG's fragment scheme is defined in the SVG documentation and looks similar to XML's. MPEG has one defined but I could only find it as an ISO document "Text of ISO/IEC FCD 21000-17 MPEG-12 FID" and not as an RFC which is a little disturbing.
AJAX. AJAX websites have used fragments as an escape hatch for two issues that I've seen. The first is getting a unique URL for versions of a page that are produced on the client by script. The fragment may be changed by script without forcing the page to reload. This goes outside the rules of the standards by using HTML fragments in a fashion not called out by the HTML spec. but it does seem to be inline with the spirit of the fragment in that it is a subview of the original resource and interpretted client side. The other hack-ier use of the fragment in AJAX is for cross domain communication. The basic idea is that different frames or windows may not communicate in normal fashions if they have different domains but they can view each other's URLs and accordingly can change their own fragments in order to send a message out to those who know where to look. IMO this is not inline with the spirit of the fragment but is rather a cool hack.

 With the new features of IE8 there's several easy ways to integrate Gmail, Google's web mail service, for mail composition, searching, and monitoring that I enjoy using.
With the new features of IE8 there's several easy ways to integrate Gmail, Google's web mail service, for mail composition, searching, and monitoring that I enjoy using.




 Some rights reserved
Some rights reserved